Features
This page introduces important key features of aedifion.io.
Overview¶
This page offers a brief and high-level description of all important features of the aedifion.io platform roughly sorted by the different steps of a typical data processing pipeline: We start with the different ways of ingressing data, continue with the functional aspects of the storage, processing, and management of data, then move on to the egress of data as well as the generation of higher level insights from the data and, finally, conclude with non-functional features such as security, privacy, and the legal framework.
Data ingress¶
aedifion.io offers plant-, building-, and even district-wide data acquisition from diverse data sources. The platform speaks most industry bus communication standards and can automatically ingest data from your plant, building, or district using auto-discovery of all available datapoints and devices for easy set-up. Furthermore, the platform integrates various other IP-based data sources, e.g., ranging from your existing legacy databases and servers over your Exchange server to third-party data sources such as weather forecasts. Finally, live data can be streamed directly into aedifion.io via MQTT while historic and batch data can be ingested using file upload in different formats such as CSV.
| Data source | Example |
|---|---|
| Automation networks | BACnet, Modbus, KNX, M-Bus, OPC UA/DA, ... |
| Databases | Different flavors of SQL and NoSQL, Influx, OpenTSDB, ... |
| Third party APIs | MS Exchange, weather data and forecasts, ... |
| User | MQTT stream, file upload, ... |
aedifion.io works fully plug-and-play for BACnet systems. All it needs is the aedifion.io Edge Device that operating personnel simply connect to the local (building) network. Once plugged in, the Edge Device connects automatically to our servers and we configure, start, and continuously monitor the data ingress.
Learn more? Explore our data import and export tutorial.
Meta data¶
For each integrated device and datapoint, aedifion.io is able to acquire and maintain comprehensive meta data either directly via the automation network, e.g., reading BACnet properties or Modbus plant descriptions, or from local databases and servers such as OPC. All meta data is automatically structured in aedifion.io's data model and can be used from thereon to search and sort the data as well as to enrich it further using artificial intelligence methods such as clustering and classification.
AI-generated meta data¶
Our platform augments the existing the meta data obtained from the automation network with Artificial Intelligence (AI)-generated information. Each datapoint and its observations are analyzed and an AI generates annotations from a set of predefined classes. The newly generated descriptions can be searched and filtered to organize your building. Since this is a statistical decision process, each annotation also provides a probability on the AI's confidence.
Weather and weather forecast data¶
aedifion.io automatically supplies local weather data and forecast data for each project, depending on its GPS coordinates.
Learn more? Explore what weather data is available on aedifion.io.
Data storage and resolution¶
For high-volume time series data, aedifion.io uses specialized time series databases that, among others, allow highly efficient queries and processing over time ranges of that data. To increase processing and storage efficiency, new observations for a datapoint are only stored when there is a (significant) change w.r.t. the previously observed/measured values. This is a common practice referred to as Change-of-Value (CoV). The preconfigured CoV threshold is 0.
Time series data can be stored at a maximum resolution of nanoseconds on aedifion.io. However, when ingesting data from an automation network, the resolution is usually limited by the maximum sampling frequency that the devices on the automation network support. Older BACnet devices, e.g., usually support sampling frequencies up to \(\frac{1}{5s}\) while modern BACnet devices can often be sampled at \(\frac{1}{s}\) and faster. Sample rates can be flexibly adjusted per project, device, and even per datapoint.
Data provision¶
aedifion.io offers various ways of data provision, i.e., via a web frontend, via rest and streaming APIs, as well as via integrations into third party software.
Frontend¶
The aedifion.io web frontend offers, among other features, search of data and meta data, different means of personalization, various flavors of plots, and export of data.
Learn more? Explore the frontend guide or visit our frontend at www.aedifion.io.
HTTP API¶
All functionality of aedifion.io is exposed through the HTTP API. Thus, it covers all functionality of the frontend and more. The API can be used with various third party tools or called from virtually any modern programming language. At https://api.aedifion.io/ui/, you can find a web environment for user‐friendly testing and compilation of API interactions. In addition, other retrieval methods can be provided for e.g. MATLAB upon request.
Learn more? Explore our HTTP API tutorials or try out our API user interface at https://api.aedifion.io/ui/.
MQTT API¶
The MQTT API offers a publish/subscribe model to stream data into and from the aedifion.io platform. You can subscribe to the data of your whole plant or limit your subscriptions to a few selected datapoints of interest.
Learn more? Try out our MQTT API tutorials.
Third party software¶
We are integrating access to data on aedifion.io into a growing amount of third-party software such as Microsoft Excel.
Learn more? Explore the overview of existing integrations.
Data processing¶
A growing range of post-processing methods is continuously being built directly into the aedifion.io platform such as down sampling, interpolation, or different general-purpose statistical analyses. Beyond the built-in functionality, you can set up custom stream and batch processes and deploy virtual datapoints that run on your project's data.
aedifion.io offers data processing in compliance with the German VDI 6041 "Technical Monitoring" and the international ISO 50 001 "Energy Management" standards.
Stream¶
Stream processes cover use cases such as nominal-actual-comparisons as required in the German VDI 6041 "Technical Monitoring" standard. A stream process runs a calculation of a free-to-choose mathematical relationship on each new event/observation of a referred datapoint. Stream processes relate to one or more datapoints.
Examples for stream processes
- Heat flow calculation: \(\dot{Q} = \dot{m} \cdot c_{p} \cdot \left( \vartheta_{out} - \vartheta_{in} \right)\)
- Coefficient of performance: \(\eta = \frac{\dot{Q}_{th}}{P_{el}}\)
- System sanity/operation checks: \(\text{actual value} \approx \text{expected value}\)
Batch¶
Batch processes cover more complex calculations and account for the more complex use cases of the ISO 50 001 "Energy Management" standard. A batch process is not operated continuously - like stream processes - but on a certain trigger, e.g., a pre-set time or up on your request. This process can run complex calculations using high-volumes of historical data.
Examples for batch processes
- Energy Efficiency Ratio (heat pump)
- Energy reporting over long periods
- Control loop analysis
Virtual datapoints¶
A virtual datapoint is a datapoint not gathered from a local plant but denotes a predefined stream or batch process that runs on one or multiple datapoints. The virtual datapoint makes the output continuously available in the form of a new datapoint in aedifion.io's time series database.
You can choose from a continuously growing list of virtual datapoints engineered and provided by aedifion and apply them to your project. Of course, all alarming and notification paradigms that run on the original physical datapoints can also be used on such virtual datapoints. This allows you, e.g., to monitor and receive alerts on complex relationships and conditions.
Examples for virtual datapoints
- Heat flux determination from temperature and volume flow sensors
- Compliance with operating rules, e.g. by correlating valve positions
- Determination of current KPI values like coefficients of performance
Data management and structuring¶
Your building or plant can easily comprise thousands of datapoints and managing these can quickly become a complex task. Thus, aedifion.io offers different methods to manage and structure data as well as to enrich it with meta data.
Favorites¶
You can flag any datapoint as a favorite, e.g., to mark frequently inspected or important datapoints. Using the frontend or API, you can filter the list of datapoints by favorites in order to quickly access them.
Tags¶
Tags are small pieces of meta data that are attached to devices and datapoints. Tags are automatically added by aedifion from the collected meta data as well as using artificial intelligence methods. Of course, users can freely add their own tags. Tags can then be used to filter devices and datapoints, to match analysis algorithms, or to build up structured naming schemes such as Brick or BUDO.
Datapoint keys¶
A datapoint key is a datapoint naming scheme that groups alternate names for all or some datapoints of a building under a common key. Alternate datapoint keys are required, e.g., to address needs of different datapoint naming schemes such as Brick or BUDO, logical uniqueness, or simply individual user preferences.
Learn more? Explore our tutorials on favorites, tagging, and renaming.
System tags¶
On the cloud-platform aedifion.io, additional information can be added to, e.g., datapoints, using tags. Tags can be assigned to datapoints either via the API or the frontend. Some tags can be used platform-wide and are therefore aggregated to system tags.
An example of a system tag represents the unit of observations, which supplements the pure timeseries information. The unit can either be set directly by the user as a tag, determined by our AI or be imported from the automation system. Tags can be set from multiple sources, these are then aggregated by our system. During aggregation, the unit set by the user is always preferred. If no unit is defined by the user, either the unit set by our AI or the unit imported from the automation system is used. Our system then selects one of these units based on a statistical evaluation.
If the unit is set and defined system-wide, the cloud-platform aedifion.io can use this information. For example, it is possible to define the unit for exporting the timeseries data via our API and thus convert values between different units during the export. In addition, the display of the timeseries on the pages can also be customized as the timeseries data in the Datapoints, in the AI Controls are displayed in the selected unit.
Project, user, and permission management¶
Each customer on aedifion.io is managed within his/her own realm such that data and meta data of that customer are always strictly separated from the resources of other customers. Each customer can have multiple projects on aedifion.io which correspond to administrative sub-realms within that company. Users can be freely added to the company and be flexibly assigned to or removed from the company's projects.
Access to all resources within a company and its projects is strictly controlled through a role-based access control (RBAC) mechanism which allows flexible and fine-grained rights management, e.g., you can restrict users' access to specific projects, to a subset of API endpoints, or even to single datapoints or tags. The RBAC system allows you to configure aedifion.io to meet your individual data privacy requirements.
Learn more? Explore our administration tutorial.
Dashboard¶
On demand, aedifion provides a separate dashboard for each project. The dashboard allows you to easily build your own visualizations on your project's data dragging-and-dropping from a wide range of plots, charts, and widgets.
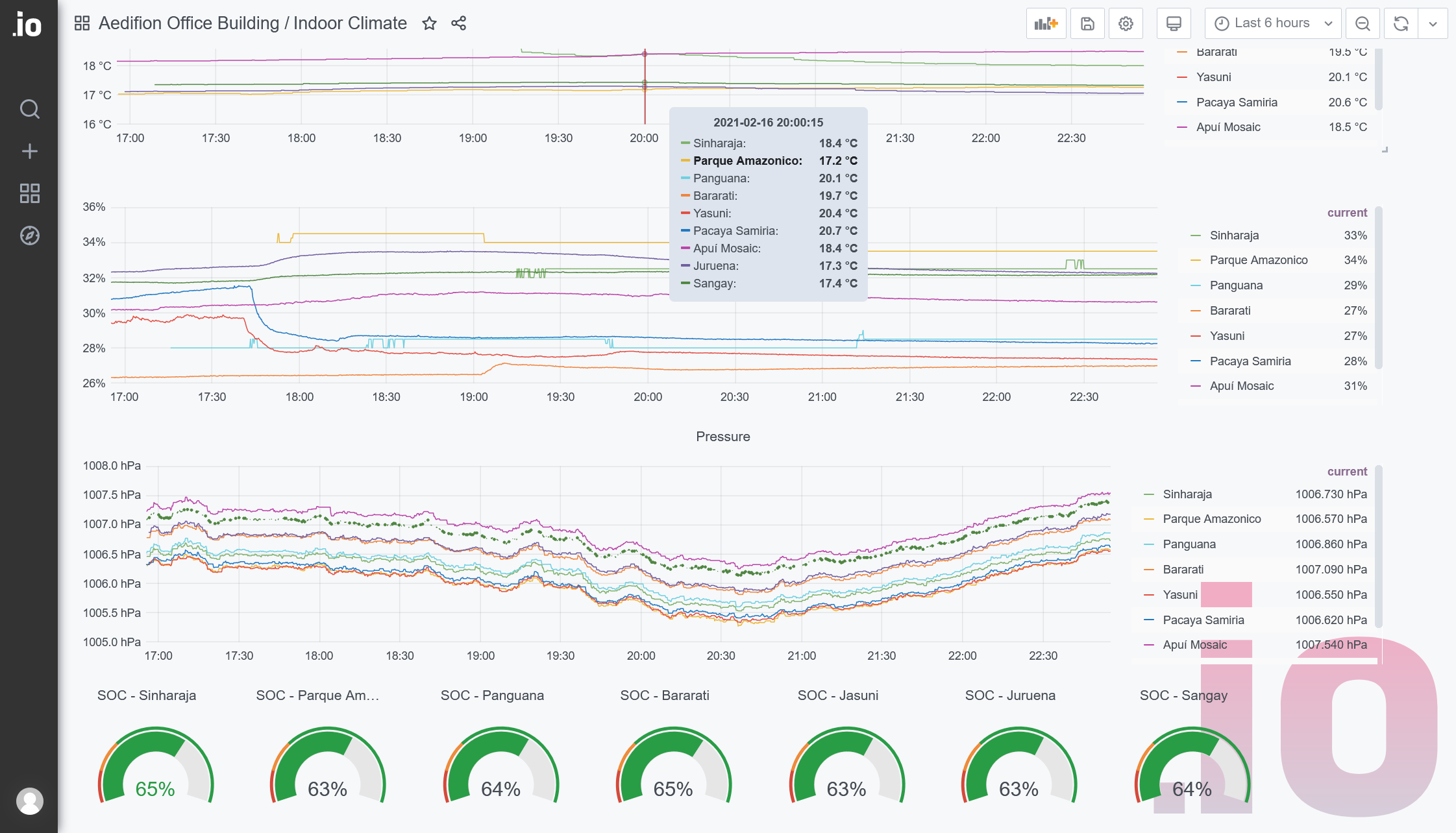
Figure 1: Example of a custom dashboard for monitoring comfort in an office
Alarming and notifications¶
aedifion.io has various alarming schemes built-in that you can deploy on projects and datapoints. Threshold alarms trigger alerts, e.g., when the CO2 concentration rises too high, while throughput alerts can be used to monitor the health of your sensors. Alerts are delivered through different alarming channels, such as web, email, instant messengers, or voice output using, e.g., Amazon's Alexa. This accounts for flexible, user-centric and innovative alarming functionalities. An example of the aedifion.io alarming web frontend is shown below in figure 2.
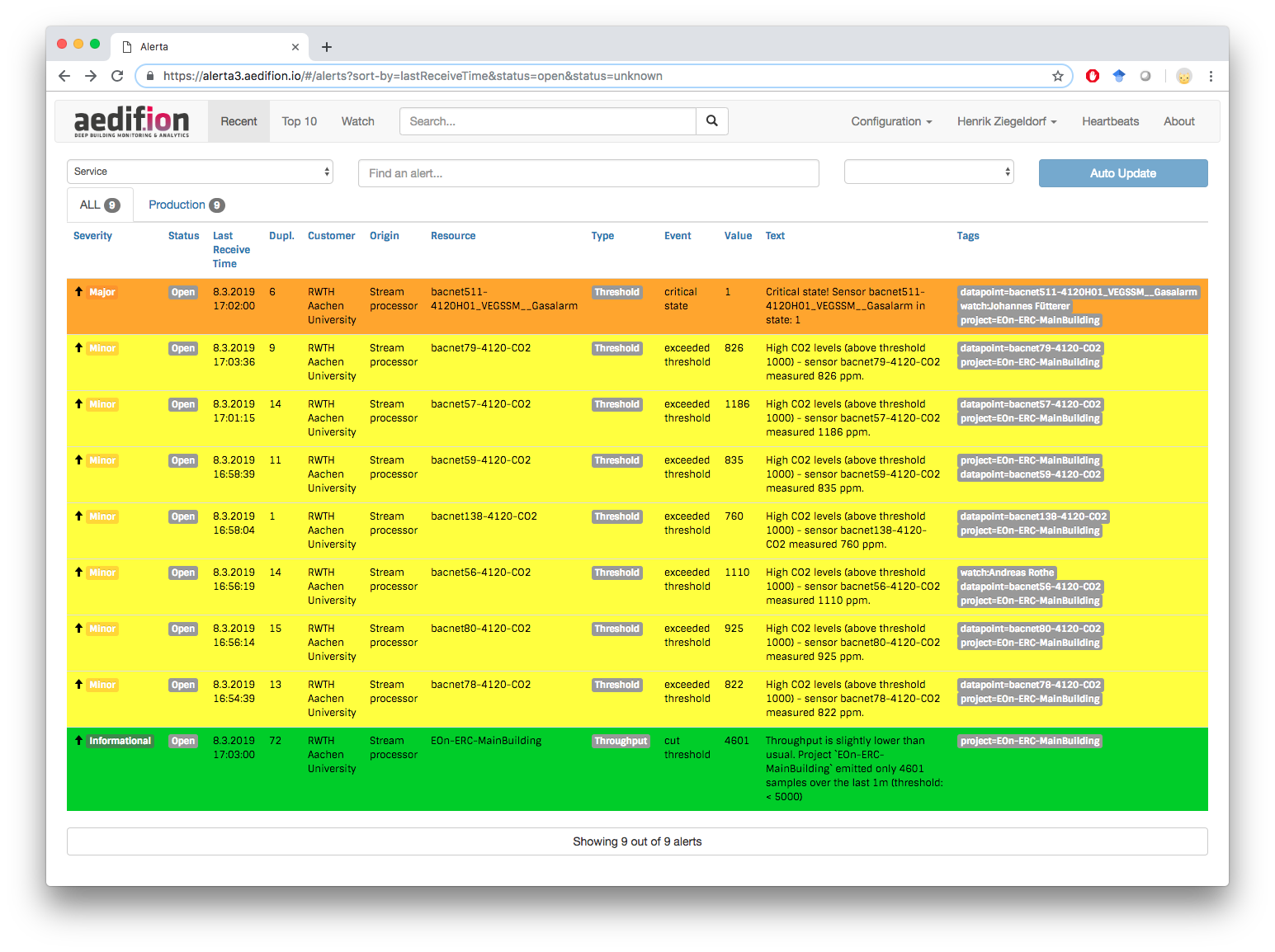
Figure 2: aedifion alarming frontend
Learn more? Explore our alarming tutorial.
Integrations¶
We continuously build integrations of aedifion.io with and into various popular third services such as cloud providers, instant messengers, Amazon's Alexa, or 3D visualizations. These integrations augment aedifion's core services and allow you to chain aedifion.io with other services to build whole new creative and innovative service pipelines.
Learn more? Read about the existing integrations.
Basic setpoint management, schedules and system overwrite¶
aedifion.io provides basic control functions whenever a datapoint is generally controllable in the field. This covers simple setpoint writing as well as manipulating local control loops or even overwriting local system output. Further, aedifion.io can provide a decent scheduling functionality that allows you to robustly execute control sequences on the aedifion Edge Device and monitor and control the execution from cloud as well as to even chain control to our integrations such as Alexa. In extreme cases, local control hardware can be reduced to in-out-devices whereas all logic is operated in the cloud.
Safety of cloud-based controls is critical. So this part of aedifion.io has to be setup manually by aedifion. All setpoints and schedules written are being logged.
Authentication mechanisms¶
aedifion.io supports various (single-sign on) authentication methods, e.g., HTTP Basic Auth, OpenID Connect, OAuth 2.0, and SAML 2.0. aedifion.io can connect to existing user directories, e.g., LDAP and Active Directory, and supports different social logins, e.g., Google, Github, Facebook and the likes.
Legal framework¶
aedifion.io's legal framework consists of a license agreement (Nutzungsvertrag) between the customer and aedifion with attachments. I.e. the aedifion Terms and Conditions (AGBs), a contract for the commissioned data processing (Auftragsdatenverarbeitung, ADV), and technical and organizational measures for data security (technisch-organisatorische Maßnahmen, TOMs).
Availability and quality assurance¶
aedifion continuously supervises aedifion.io's system health using internal realtime measurements along the whole data pipeline, i.e, from collection of data over its storage and processing all the way to the output of data and generated insights.
aedifion.io can be mirrored across two identical but completely independent deployments that work redundantly in parallel. All time series data is backed up on a weekly basis while backups of all meta data are created each night. Backups are kept for the whole duration of the project.
aedifion.io runs in cloud, edge, and air-gapped deployments.